Alex AndersonHello! My name is Alex and I am a research engineer at Apple SPG. In the past, I was a research scientist at WaveOne. I worked with Bruno Olshausen in the Redwood Center for Theoretical Neuroscience during my Ph.D. In the summer of 2016, I interned at Oculus Research. In the past, I graduated summa cum laude at Washington University in St. Louis with a double major in math and physics. I did my undergraduate thesis with Carl Bender. Before that, I enjoyed high school math competitions. |

|
Representative Work
|
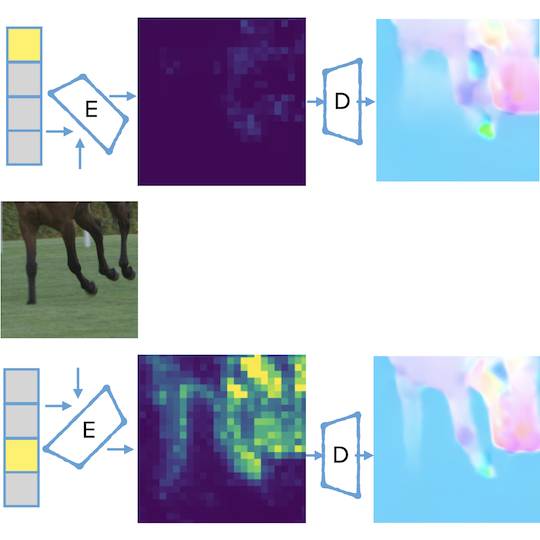
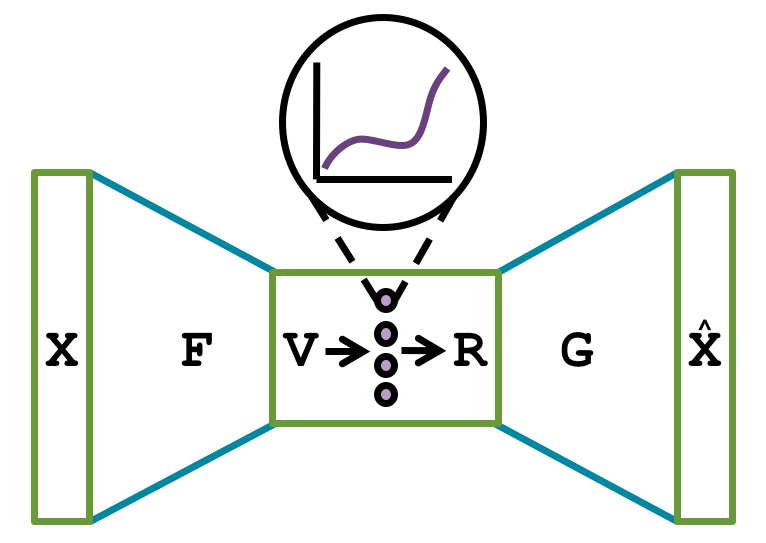
Conference Paper: ELF-VC: Efficient Learned Flexible-Rate Video Coding
Oren Rippel*, Alexander G Anderson*, Kedar Tatwawadi, Sanjay Nair, Craig Lytle, Lubomir Bourdev (*Equal Contribution) International Conference on Computer Vision (October 16th, 2021)
First learned video compression model to outperform the standards on PSNR, MS-SSIM, and VMAF while decoding 720p video in real time. Furthermore, the model supports a wide range of the RD curve with a shared set of parameters. Paper | Project Page
|
|
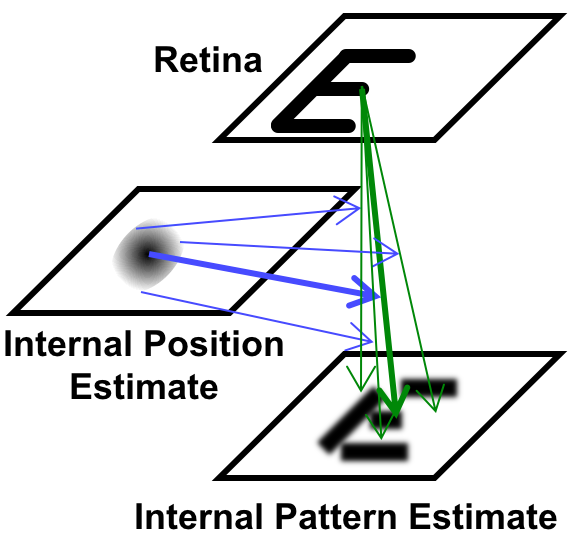
Journal Article: High-Acuity Vision from Retinal Image Motion
Alexander G. Anderson, Kavitha Ratnam, Austin Roorda, Bruno Olshausen Journal of Vision (July 2020)
A mathematical model shows how the eyes' self-generated drift motion can improve high-acuity vision by averaging over retinal inhomogeneities. Paper
|
|
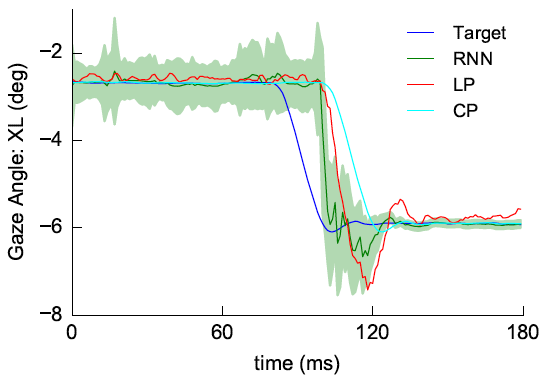
Thesis Chapter: Latency Compensation with Recurrent Neural Networks for Gaze Contingent Displays
Alexander G. Anderson, Alexander Fix, Rob Cavin, Aaron Nicholls Oculus Perceptual Science Team (May 2018)
State of the art eye movement prediction using RNNs, including a new architecture for dealing with noisy data. Paper (Ch 3.) (If the link breaks, search Alexander G Anderson Thesis Berkeley).
|
|
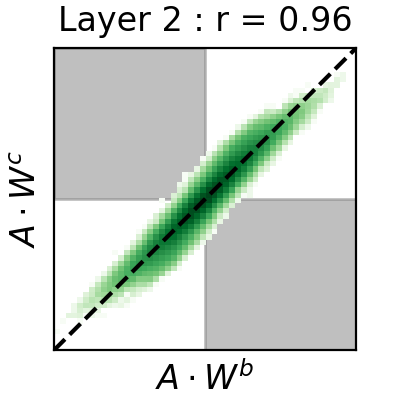
Conference Paper: The High Dimensional Geometry of Binary Neural Networks
Alexander G. Anderson, Cory P. Berg International Conference on Learning Representations (ICLR) Conference Track (April 30th, 2018)
Recent successes of Binary Neural Networks can be understood based on the geometry of high-dimensional binary vectors. Paper | Code
|
|
Conference Paper: Joint Source-Channel Coding with Neural Networks for Analog Data Compression and Storage in Emerging Devices.
Ryan Zarcone, Dylan Paiton, Alexander G. Anderson, Jesse Engel, H.S. Phillip Wong, Bruno A. Olshausen. Data Compression Conference (March 27th, 2018)
Neural networks are used to store images in noisy memory devices. Paper
|

|
Technical Report: DeepMovie - Using Optical Flow and Deep Neural Networks to Stylize Movies
Alexander G. Anderson, Cory P. Berg, Daniel P. Mossing, Bruno A. Olshausen Berkeley (May 2016)
Style Transfer for Movies. See the Video for a clip of Star Wars in the Art Style of Vincent Van Gogh. Paper | Video
|
Extended Projects

|
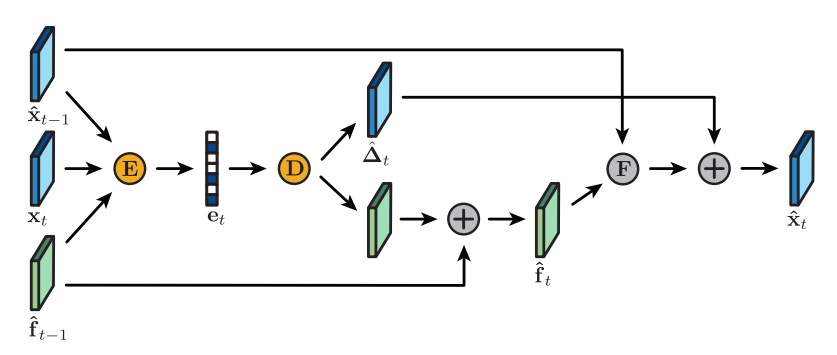
Conference Paper: An Interactive Annotation Tool for Perceptual Video Compression
Evgenya Pergament, Pulkit Tandon, Kedar Tatwawadi, Oren Rippel, Lubomir Bourdev, Bruno Olshausen, Tsachy Weissman, Sachin Katti, Alexander G. Anderson International Conference on Quality of Multimedia Experience (QoMEX) (September 6, 2022)
Annotation tool to improve perceptual quality of h264 compressed videos by brushing areas that are more important and encoding with two pass target bitrate encoding. Paper
|
|
Conference Paper: Learned Video Compression
Oren Rippel, Sanjay Nair, Carissa Lew, Steve Branson, Alexander G. Anderson, Lubomir Bourdev International Conference on Computer Vision (ICCV) (October 27, 2019)
End-to-end learned model for low-latency video compression is shown to outperform the standards. Paper
|
|
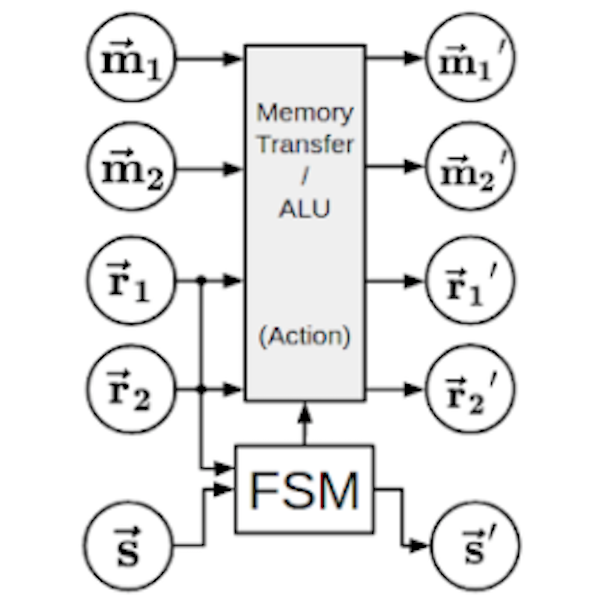
Conference Poster: The Hyperdimensional Stack Machine: Robust Computing with Distributed Representations
Thomas Yerxa, Alexander G. Anderson, Eric Weiss Cognitive Computing, Merging Concepts with Hardware (Dec. 18-20, 2018)
High-dimensional vectors are used to implement a fault-tolerant, interpretable, and differentiable stack. The stack is then used to reverse sequences and parse reverse polish notation expressions.
|
|
Conference Poster: Motion Selectivity of Neurons in Self-Driving Networks
Baladitya Yellapragada, Alexander G. Anderson, Stella Yu, and Karl Zipser Perceptual Organization in Computer Vision (POCV) Workshop on Action, Perception and Organization at ECCV (September 9th, 2018)
Neural networks trained to drive cars directly from video are shown to do optical flow-like computations. Paper
|
|
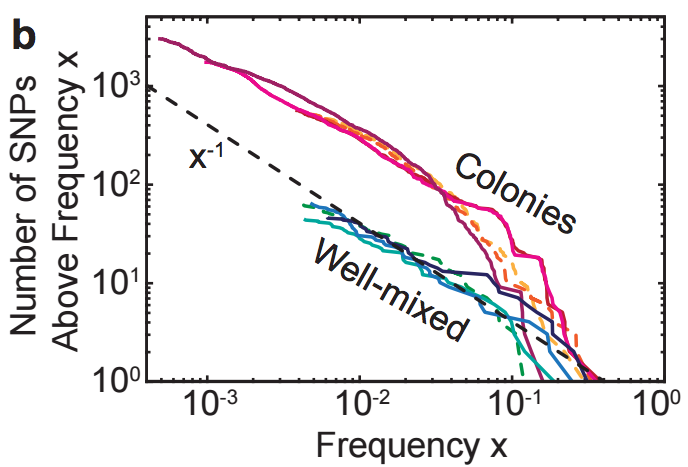
Journal Article: Excess of mutational jackpot events in growing populations due to gene surfing
Diana Fusco, Matti Gralka, Jona Kayser, Alexander G. Anderson, Oskar Hallatschek Nature Communications (Oct 2016)
Mutations propagate differently throughout a population depending on the spatial structure of the habitat. Paper
|

|
Personal Project: Artistic Style Transfer in TensorFlow
Alexander G. Anderson Berkeley (2016)
Implementation of Artistic Style Transfer in TensorFlow Another Photo
|
|
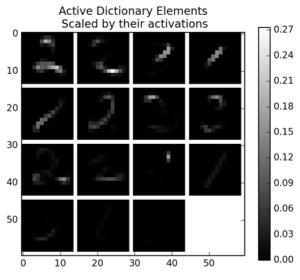
Tutorial: Sparse Coding Tutorial
Alexander G. Anderson, Jesse Livezey, Guy Isley, Charles Frye Redwood Center for Theoretical Neuroscience (July, 2015)
Co-wrote code and led a tutorial on Sparse Coding for incoming Berkeley Neuroscience students. Link
|
|
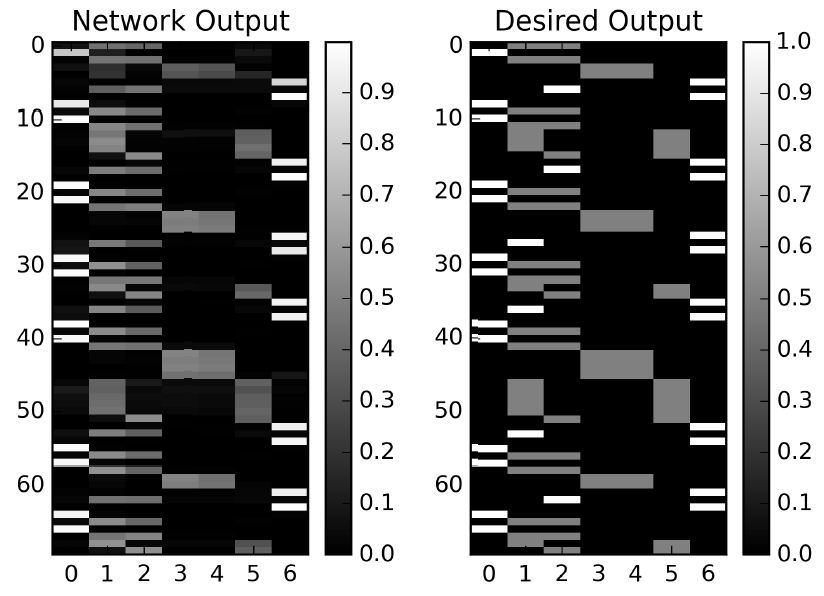
Class Project: Analyzing the Internal Dynamics of a LSTM Trained to Solve the Reber Grammar
Alexander G. Anderson Redwood Center for Theoretical Neuroscience (2014)
Implemented a LSTM in theano and analyzed the hidden dynamics that give rise to the solution of the Reber Grammar problem.
|
|
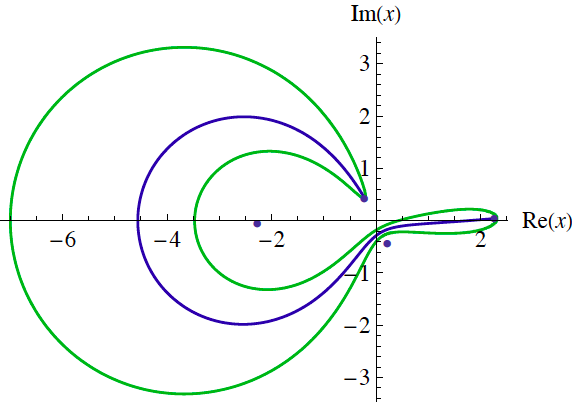
Journal Article: Complex Trajectories in a Classical Periodic Potential
Alexander G Anderson and Carl M Bender Journal of Physics A Mathematical and Theoretical (2012)
|

|
Journal Article: Periodic Orbits for Classical Particles Having Complex Energy
Alexander G Anderson, Carl M Bender, and Uriel I. Morone Physics Letters A (2011)
|
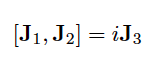
|
Independent Project: The Algebra of Noncommutative Operators
Alexander G. Anderson, Henry Maltby, Jing Jing Li Berkeley Math Tournament Power Round (2013)
A proof-based round for a high school math contest about an important mathematical tool used in quantum mechanics. Problems | Solutions
|
|
Curriculum Design: AwesomeMath Summer Course in Intermediate Geometry
Alexander G. Anderson, Joseph Tkadlec AwesomeMath Summer Camp (2010, 2012)
Fourteen ninty minute lectures and ninty minute problem solving sessions for high school students excited about math competitions.
|
|
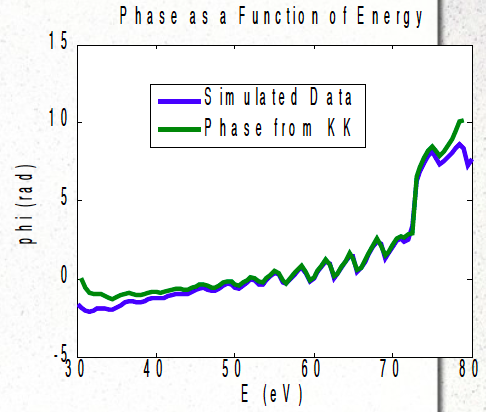
Summer Research: Phase Determination of Multilayer Mirrors using the Kramers-Kronig Relations
Alexander G. Anderson, Charles Bourassin-Bouchet, Sebastien de Rossi, Franck Delmotte (2011)
Determined that a potential new method of characterizing Multilayer mirrors was infeasible.
|
|
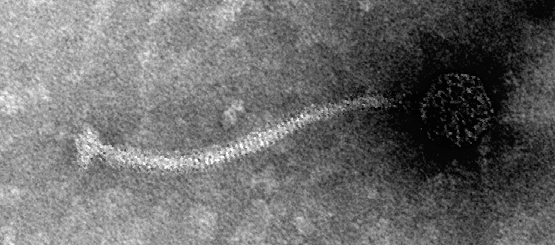
Class Project: Isolation and Characterization of Mycobacteriophage Uncle Howie
Alexander G. Anderson Phage Hunters Class (2008)
|
{kind=link}